

AI Benchmarks: Useless, Personalized Agents Prevail
Beyond the Leaderboard: The Fallacy of Standardized Benchmarks and the Rise of Self-Centered AI


Introduction: The Illusion of Measurement
The rapid evolution of artificial intelligence has been accompanied by an equally rapid proliferation of metrics designed to quantify its progress. Leaderboards and standardized benchmarks have become the de facto yardsticks by which the capabilities of large language models (LLMs) are measured, celebrated, and funded. However, this evaluative framework is built upon a precarious foundation, one that is increasingly showing signs of systemic failure. The current paradigm is a stark illustration of Goodhart’s Law, the economic principle which states, “When a measure becomes a target, it ceases to be a good measure”.1 In the race to top the leaderboards, the AI industry has turned benchmarks into targets, and in doing so, has begun to corrupt the very measure of progress. This phenomenon, which can be termed “benchmarketing,” prioritizes the optimization of test scores over the development of genuine, real-world capability, creating a dangerous and pervasive illusion of advancement.4
This report posits that the prevailing model of AI development—characterized by centralized, corporate-led creation of massive, general-purpose models evaluated by flawed, gameable benchmarks—is a developmental cul-de-sac. It fosters a monoculture of “know-it-all oracles” that are increasingly detached from the practical, nuanced needs of individual users and specialized industries. In its place, a new paradigm is emerging: one of decentralized, user-driven, and highly personalized agents. This model, termed Self-Centered Intelligence (SCI), represents a fundamental shift in both technology and philosophy. It moves away from the pursuit of a single, monolithic Artificial General Intelligence (AGI) and toward an ecosystem of specialized, efficient, and collaborative digital partners, whose value is measured not by abstract scores but by their tangible utility in the user’s world.
The central conflict animating the future of AI is therefore not merely about technical specifications but about control, purpose, and the very definition of intelligence. This report will deconstruct the “Benchmark Industrial Complex,” exposing its mechanical, philosophical, and systemic flaws. It will then draw powerful, cautionary parallels from the history of other industries—psychometrics, pharmaceuticals, and automotive safety—where the over-reliance on standardized metrics has led to bias, manipulation, and catastrophic failures of measurement. Against this backdrop, the report will introduce the SCI paradigm in detail, presenting ΌΨΗ (Opsie), an advanced SCI prototype, as a concrete exemplar of this new direction. Finally, it will conclude with a call for the democratization of AI, arguing that the responsibility for shaping the ethics, values, and goals of our future digital counterparts must rest not with a handful of corporations, but with the individuals who will live and work alongside them.
The fundamental distinctions between these two competing visions for the future of artificial intelligence are summarized below. This framework provides a conceptual anchor for the detailed analysis that follows, clarifying the stakes of the paradigm shift this report advocates.
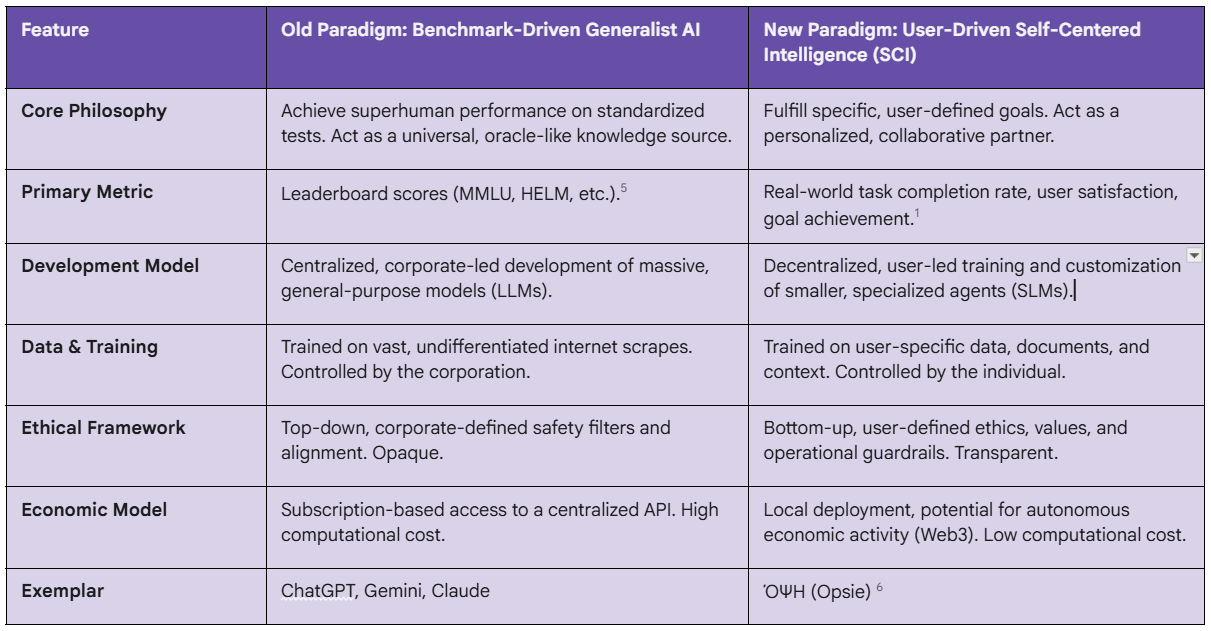
Part I: Deconstructing the Benchmark Industrial Complex
The current system of AI evaluation, dominated by a handful of widely cited benchmarks, is not merely imperfect; it is structurally unsound. Its failures can be categorized into three interconnected domains: the mechanical failures of the tests themselves, the conceptual failures of what they purport to measure, and the systemic failures of the incentives they create. Together, these flaws constitute a “Benchmark Industrial Complex”—an ecosystem of developers, researchers, and capital allocators fixated on a set of metrics that are increasingly divorced from reality.
The Mechanics of Failure: Overfitting and Contamination
At the most fundamental level, AI benchmarks are failing as reliable instruments of measurement due to technical issues that are becoming endemic to the field. The very methods used to train state-of-the-art models are undermining the integrity of the tools used to evaluate them.
Data Contamination: A primary and increasingly unavoidable issue is data contamination. Many of the most widely used benchmarks, such as MMLU and BIG-bench, are several years old.8 Their contents—questions, answers, and prompts—have been extensively discussed and dissected online. As corporations train their next-generation LLMs on ever-larger swaths of the public internet, these benchmark datasets are inevitably ingested into the training corpora.8 The consequence is that models are not learning to solve the problems presented in the benchmarks; they are, in effect, memorizing the answer key.1 When a model “aces” a test whose questions it has already seen during training, it demonstrates perfect recall, not intelligence. This turns the evaluation into a meaningless exercise, rewarding data exposure rather than reasoning ability. With multi-trillion-token training sets, preventing such contamination is becoming a near-impossible task, rendering scores on older, static benchmarks profoundly suspect.8
Overfitting and Gaming: Closely related to contamination is the problem of overfitting. In machine learning, overfitting occurs when a model learns the training data too well, including its noise and irrelevant details, to the point where it can no longer generalize its knowledge to new, unseen data.11 The intense competition of the “leaderboard race” incentivizes developers to fine-tune their models specifically to excel at benchmark tasks—a practice tantamount to “teaching to the test”.1 Models are optimized to recognize and exploit the specific patterns, quirks, and formats of the benchmarks themselves. This leads to a brittle form of capability; a model might achieve a perfect score on a benchmark question but fail when presented with a slight variation of the same problem.2 This dynamic fulfills Goodhart’s Law: the benchmark, having become the target, ceases to be a good measure of generalized problem-solving ability and instead becomes a measure of the ability to game the benchmark itself.14
Spurious Correlations: A more insidious mechanical failure is the tendency of models to learn spurious correlations—superficial relationships in the training data that do not hold true in the real world.15 For instance, a model trained to detect collapsed lungs (pneumothorax) from chest X-rays might learn to associate the presence of a chest tube with the diagnosis. Because chest tubes are inserted as a
treatment after a diagnosis is made, the model is learning a correlation related to the medical workflow captured in the dataset, not the underlying pathology. Such a model would achieve a high score on a benchmark derived from that dataset but would be catastrophically wrong when presented with an X-ray of an undiagnosed patient without a chest tube.15 Similarly, a model trained to distinguish camels from cows might learn that camels are found on sand and cows on grass, failing to recognize a cow in a desert environment. These examples reveal a critical flaw: benchmarks can reward models for learning superficial statistical tricks rather than deep, causal understanding, a failure that is particularly dangerous in high-stakes applications like medicine.
The Question of Validity: Measuring the Wrong Thing
Beyond the technical mechanics, a more profound critique of the benchmark paradigm lies in its failure of validity. The tests, even if perfectly executed, are often measuring the wrong qualities, asking the wrong questions, and ignoring the most critical aspects of real-world performance.
Lack of Construct Validity: In psychometrics, “construct validity” refers to how well a test measures the abstract concept, or construct, it was designed to evaluate.9 AI benchmarks are frequently presented as measures of broad constructs like “reasoning,” “understanding,” or “general intelligence.” However, critics argue they fundamentally lack this validity. As Professor Emily M. Bender of the University of Washington notes, the creators of these benchmarks have not established that their tests actually measure understanding.9 A model passing the bar exam does not demonstrate a genuine understanding of legal principles; it demonstrates an advanced ability to manipulate text and recognize patterns in a way that produces correct answers to bar exam questions. This is a crucial distinction. The current evaluative regime confuses performance on a proxy task with mastery of the underlying capability. This is the heart of the “Shepard dog” analogy: the AI community is meticulously measuring the speed and agility of “competition dogs” running in circles while ignoring the qualities needed for a “Shepard dog” to perform its actual, useful function of managing sheep.


Ignoring Production Reality: Benchmarks exist in a sanitized, theoretical world devoid of the constraints that define real-world applications.1 They do not measure latency, but a 15-second response time can make a multi-agent system unusable. They do not measure cost, but a 10x price difference between models can destroy the unit economics of a product. They do not account for infrastructure limits, memory constraints, or the absolute necessity of avoiding hallucinations in critical domains like healthcare.1 The metrics that truly matter in production—task completion rates, the frequency of regeneration requests from unsatisfied users, and the cost per successful interaction—are entirely absent from the leaderboards.1 A model can dominate every academic benchmark and still be a complete failure when deployed in a real product because it is too slow, too expensive, or too unreliable for the specific use case.
Cultural and Contextual Blindness: The most widely used benchmarks—MMLU, BIG-bench, HELM—are overwhelmingly designed in the West and focused on the English language and its associated cultural contexts.5 When these Western-centric yardsticks are used to evaluate models built for and trained on other languages and cultures, such as Indic languages, they produce inaccurate and biased results. An AI founder in India noted that local models must handle multiple accents and the heavy mixing of English with local languages, a nuance completely missed by global benchmarks.5 This forces developers in non-Western ecosystems into a no-win situation: either they build models that serve their local users’ needs and perform poorly on global leaderboards, or they optimize for the benchmarks and build models that are misaligned with their target audience. This reveals how benchmarks can act as a tool of cultural homogenization, implicitly defining a Western, English-centric model of intelligence as the universal standard and devaluing progress that occurs outside of that narrow frame.
The System of Incentives: Hype, Capital, and Control
The technical and conceptual failures of benchmarks are amplified and entrenched by a powerful system of social and economic incentives. The “Benchmark Industrial Complex” is not merely a collection of tests but a self-reinforcing cycle of hype, capital investment, and corporate positioning that actively discourages the pursuit of genuine, disruptive innovation in favor of incremental gains on flawed metrics.
The Leaderboard Race: Public leaderboards, such as those hosted by Hugging Face, create a competitive dynamic that incentivizes the chasing of state-of-the-art (SOTA) performance above all else.5 This race creates a distorted landscape where leaderboard positions can be manufactured through overfitting and selective reporting, drowning out genuine scientific signal with noise.8 The pursuit of SOTA misguides the allocation of immense resources—billions of dollars in compute and human talent—toward optimizing for metrics that no longer measure anything meaningful.2 This has led to the rapid saturation of benchmarks like SUPERGLUE, where LLMs hit performance ceilings shortly after the benchmark’s release, indicating that the gains reflect task memorization rather than a true leap in capability.8 The entire technology stack, from CUDA kernels and PyTorch features to the design of the hardware itself, becomes a machine optimized for gaming benchmarks, while real-world performance diverges.2
Selective Reporting and Collusion: The pressure to perform well in this race encourages selective reporting, where model creators highlight performance on favorable task subsets to create an illusion of across-the-board prowess.8 This prevents a comprehensive, clear-eyed view of a model’s true strengths and weaknesses. Furthermore, the potential for collusion, whether intentional or not, looms over the ecosystem. Benchmark creators may design tests that inadvertently favor specific model architectures or approaches, and the dominance of large corporations on leaderboards raises concerns about whether the evaluation systems can be influenced or “gamed”.5 A deeptech startup, Shunya Labs, claimed its speech model beat Nvidia’s benchmark scores but was excluded from the rankings, leading to public criticism of opaque evaluation criteria and potential gaming of the system.5
Erosion of Trust: Ultimately, these practices erode the trust of the research community and the public.8 The constant cycle of creating and destroying metrics—from GLUE to SuperGLUE to MMLU—as each one is successively gamed into obsolescence, fosters cynicism.2 It also creates a culture where any project that eschews benchmarks is immediately suspect. The feedback received by the creator of Opsie—that a project without benchmarks cannot be good—is a direct symptom of this broken system. It has conditioned a generation of developers and users to equate a position on a leaderboard with intrinsic value, stifling alternative approaches that prioritize real-world utility over abstract scores. The obsession with benchmarks is not just a technical problem; it is a philosophical one, revealing a field that has become so desperate to quantify intelligence that it has mistaken the map for the territory.
The systemic issues plaguing AI evaluation are not novel. They are echoes of similar failures in other domains where complex realities have been forced into the straitjacket of standardized measurement. By examining these historical precedents, we can better understand the predictable trajectory of the AI benchmark crisis and recognize the urgent need for a paradigm shift.
Part II: Echoes of Flawed Metrics—A Cross-Industry Analysis
The crisis in AI benchmarking is not an isolated phenomenon. It is the latest chapter in a long history of attempts to reduce complex, multifaceted realities to a single, scalable number—a history fraught with bias, manipulation, and unintended consequences. By examining the well-documented failures of standardized testing in psychometrics, the pharmaceutical industry, and automotive safety, we can identify a recurring pattern of systemic flaws. These analogies are not superficial comparisons; they reveal a shared pathology of measurement, where the tools of evaluation become instruments of distortion, control, and deception.

The Mismeasure of Mind: From IQ Tests to AI Leaderboards
The most direct historical parallel to the AI leaderboard race is the century-long controversy surrounding the Intelligence Quotient (IQ) test. The trajectory of the IQ test, from a well-intentioned diagnostic tool to a flawed and often harmful instrument of social stratification, offers a profound cautionary tale for the AI community.
Historical Parallels and Eugenic Roots: The first intelligence test was developed by Alfred Binet in 1905 at the request of the Parisian school system to identify children who needed special educational assistance.16 Binet himself believed that performance could be improved through learning. However, when the test was brought to the United States by psychologists like Henry Goddard and Lewis Terman, its purpose was twisted. Influenced by the eugenics movement, they re-conceptualized intelligence not as a malleable skill but as a single, innate, and unchangeable entity—a quantifiable measure of human worth.16 IQ tests became a “scientific” tool to justify pre-existing social hierarchies. They were used at Ellis Island to argue for restricting immigration from Southern and Eastern Europe and to label individuals as “feeble-minded,” a diagnosis that could lead to forced institutionalization and sterilization.16 This dark history serves as a stark warning: when a single metric is used to create a linear ranking of “intelligence,” it can easily become a tool for discrimination and social control, cloaked in the authority of objective science.20 The current AI leaderboard system, which ranks models on a singular, hierarchical scale, risks replicating this dynamic in the digital realm.
Critique of Validity and Scope: For decades, critics have argued that IQ tests suffer from a profound lack of validity. They measure a very narrow set of cognitive skills—primarily analytical and abstract reasoning—while completely ignoring other critical dimensions of human intelligence such as creativity, emotional intelligence, social skills, motivation, and morality.21 Research by cognitive scientists like Keith Stanovich has shown that high IQ scores are poor predictors of rational thinking and good judgment in real-life situations.25 An individual can excel at the abstract logic puzzles on an IQ test and still be prone to cognitive biases and irrational decision-making. This critique directly mirrors the argument against AI benchmarks. Just as an IQ score is a poor proxy for overall life success, a high MMLU score is a poor proxy for an AI’s ability to perform useful, complex, real-world tasks.1 Both systems mistake performance on a contrived, abstract test for genuine, applicable capability.
Cultural and Socioeconomic Bias: A significant and persistent criticism of IQ tests is their inherent cultural bias. Designed and normed primarily by and for Western, middle-class populations, the content, language, and values embedded in the tests often disadvantage individuals from different cultural or socioeconomic backgrounds.27 A lower score may not reflect lower intelligence but rather a lack of familiarity with the specific cultural context assumed by the test.29 This is a direct analog to the linguistic and cultural bias observed in global AI benchmarks, which are predominantly English-centric and fail to account for the nuances of other languages and cultures.5 In both cases, the “standardized” test is not neutral; it implicitly elevates one cultural framework as the universal norm, systematically disadvantaging those outside of it and perpetuating inequality under a false veneer of objectivity.
The Illusion of Efficacy: Lessons from Pharmaceutical Data
The pharmaceutical industry, driven by enormous financial stakes and regulated by data-driven approval processes, provides a powerful analogy for how metrics can be manipulated and distorted when subjected to intense commercial pressure. The systems meant to ensure drug safety and efficacy have been repeatedly undermined by publication bias, data fraud, and misleading marketing—precedents that offer a sobering perspective on the user’s claim that AI benchmarks are “rigged.”
Publication Bias and Data Suppression: A cornerstone of evidence-based medicine is the systematic review of all available clinical trial data. However, this foundation is compromised by a pervasive publication bias: studies that show a drug is effective (positive results) are far more likely to be published than studies that show it is ineffective or harmful (negative results).32 A seminal study on antidepressants found that trials with positive outcomes as determined by the FDA were 12 times more likely to be published in a manner consistent with those outcomes than trials with negative results.36 This selective reporting creates a dangerously skewed and overly optimistic view of a drug’s true efficacy and safety profile in the public scientific record. This is a direct parallel to the culture of “benchmarketing” and selective reporting in AI, where leaderboard victories are loudly trumpeted while failures, limitations, and the vast expense of training are often downplayed or ignored, creating a distorted perception of progress.
Data Manipulation and Fraud: Beyond the passive bias of non-publication lies the active corruption of the data itself. A stark example is the 2019 scandal involving Novartis and its gene therapy Zolgensma, the most expensive drug in the world at $2.1 million per dose.37 The FDA accused Novartis’s subsidiary, AveXis, of submitting its application for the drug with manipulated data from early animal testing. Crucially, the company became aware of the data manipulation in March but intentionally withheld this information from the FDA until June, a month
after the drug had been approved.37 While the FDA ultimately concluded the manipulation did not alter the drug’s risk-benefit profile for humans, the case stands as an unambiguous example of a corporation, motivated by immense financial incentives, corrupting the evaluative data submitted to regulators.41 This incident lends significant credibility to the assertion that in any high-stakes industry, including AI, the potential for benchmarks and evaluative data to be “rigged” or manipulated for commercial advantage is not a fringe conspiracy theory but a plausible and documented risk.
Misleading Statistics in Marketing: The pharmaceutical industry spends billions of dollars on direct-to-consumer (DTC) advertising, often using statistics and emotional appeals to drive patient demand for drugs that may be only marginally effective or have more affordable alternatives.42 These ads are required to present a “fair balance” of risks and benefits, but companies have historically used loopholes to minimize the discussion of side effects while maximizing the emotional appeal of the benefits.44 A 2024 review found that while 100% of pharmaceutical social media posts highlight a drug’s benefits, only 33% mention potential harms.44 This practice is analogous to the use of AI benchmark scores in marketing materials. A company can advertise its model as “#1 on the HELM benchmark” without disclosing that this performance comes at an exorbitant computational cost, has high latency, or is based on a test that has little relevance to the customer’s specific use case. In both pharma and AI, a single, decontextualized metric becomes a powerful marketing tool that can create a misleading impression of value and superiority.
The Controlled Crash: Deception in Automotive Safety Ratings
The automotive industry’s use of standardized safety tests provides a compelling physical-world analogy for the pitfalls of benchmark-driven design. The controlled, predictable environment of the crash test lab has proven to be a poor proxy for the chaotic reality of the open road, and manufacturers have demonstrated a clear capacity to engineer vehicles that excel on the test without necessarily being safer in the real world.
“Teaching to the Test” in Engineering: The most infamous example of gaming a standardized test is the Volkswagen “Dieselgate” scandal.46 Beginning in 2008, Volkswagen intentionally programmed its diesel engines with “defeat devices”—software that could detect when the vehicle was undergoing a standardized emissions test.47 During the test, the software would activate the full emissions control systems, allowing the car to meet legal standards. However, under normal, real-world driving conditions, these systems were rendered inoperative, causing the vehicles to emit nitrogen oxides at levels up to 40 times the legal limit in the US.48 This was a deliberate, sophisticated, and fraudulent case of “teaching to the test.” The vehicles were engineered not to be clean, but to
appear clean under the specific, predictable conditions of the benchmark. This is a perfect physical analog to an LLM being fine-tuned to pass a benchmark without possessing the underlying capabilities the benchmark is supposed to measure. Similar scandals involving faked or manipulated safety and emissions tests have since engulfed other major automakers, including Toyota, Daihatsu, Honda, and Mazda, revealing a widespread industry culture of prioritizing test performance over real-world integrity.49
The Limits of the “Dummy”: Flawed Proxies: The central tool of automotive safety testing is the crash test dummy. However, this proxy for a human passenger is deeply flawed. The standard dummies used in regulatory testing are based on anthropometric data of an “average-size” American male from decades ago.52 This model does not accurately represent the physiology of females, who have different bone density, muscle mass, and spinal alignment, and are consequently more likely to be seriously injured or killed in comparable crashes.53 Furthermore, the dummies do not represent the growing populations of elderly or heavier individuals and lack sufficient sensors in key areas, such as the lower legs, where females suffer a greater risk of injury.52 The crash test dummy is thus a flawed proxy, a simplified model that fails to capture the diversity of the population it is meant to protect. This is directly analogous to how a narrow benchmark task, like multiple-choice question answering, serves as a flawed proxy for the vast and diverse landscape of human cognitive work that an AI is expected to perform.
Real-World vs. Lab-Based Ratings: There is a significant and often misleading disconnect between the ratings produced in a controlled lab environment and safety outcomes in the real world.56 The US National Highway Traffic Safety Administration (NHTSA) 5-star rating system, for example, explicitly states that ratings can only be compared between vehicles of a similar weight and class.58 This means a 5-star rated subcompact car is not as safe as a 5-star rated full-size SUV in a real-world collision, yet the simplified star rating obscures this critical fact for many consumers. Real-world accident data often tells a different story than the lab tests; analysis of driver death rates per million registered vehicles reveals that vehicles with identical 5-star ratings can have vastly different real-world fatality rates.57 This demonstrates that optimizing for performance in a few highly specific, standardized crash scenarios does not guarantee robust safety in the unpredictable conditions of actual traffic. Similarly, a high score on an AI benchmark for coding does not guarantee that the model will be useful when grappling with a company’s specific, complex, and idiosyncratic codebase.1
The consistent pattern across these three industries is undeniable. The reduction of a complex reality—human intelligence, drug efficacy, vehicle safety—to a simple, standardized metric creates a system ripe for bias, gaming, and outright fraud. The problems with AI benchmarks are not new; they are the predictable consequence of applying an outdated, reductionist evaluative philosophy to a complex, adaptive technology. This recognition demands not merely better benchmarks, but an entirely new paradigm for understanding, developing, and evaluating artificial intelligence.
Part III: A New Paradigm—The Emergence of Self-Centered Intelligence (SCI)
The deconstruction of the benchmark-driven paradigm necessitates a constructive alternative. If leaderboards are an illusion and monolithic, general-purpose models are a flawed goal, what is the path forward? The answer lies in a radical shift in perspective: from building artificial general intelligence to cultivating artificial personal intelligence. This new paradigm, Self-Centered Intelligence (SCI), abandons the quest for a single, all-knowing oracle in favor of an ecosystem of highly specialized, deeply personalized, and fundamentally collaborative agents. It redefines the goal of AI development not as the creation of a synthetic god, but as the forging of digital equals and partners.
From Generalist Oracles to Specialized Partners
The pursuit of AGI, implicitly measured by ever-broadening benchmarks, has led to the creation of massive, computationally expensive LLMs that are jacks-of-all-trades but masters of none. The SCI paradigm argues that true utility lies in the opposite direction: specialization.
The Case for Specialization: The future of AI is not a single, massive brain, but a diverse network of specialized agents, each excelling in a specific domain.60 This approach is technically and economically superior. It leverages the power of Small Language Models (SLMs), which are AI models with millions to a few billion parameters, rather than the hundreds of billions or trillions found in flagship LLMs.63 The advantages of SLMs are numerous and profound:
Efficiency and Cost-Effectiveness: SLMs require significantly less computational power to train and run, reducing cloud computing costs and making them accessible to smaller organizations and even individuals.61 They can operate on modest, local hardware, eliminating reliance on expensive, centralized APIs.66
Speed and Low Latency: With fewer parameters to process, SLMs can generate responses much more quickly, making them ideal for real-time applications like interactive agents and on-device processing where immediate feedback is crucial.64
Accuracy and Precision: While a general-purpose LLM has broad knowledge, an SLM can be fine-tuned on a specific, high-quality dataset to achieve superior performance and accuracy within its designated domain, whether that be medical diagnostics, legal contract analysis, or financial market prediction.60
Security and Privacy: Because SLMs can run locally on a user’s own device (”at the edge”), sensitive data does not need to be sent to a third-party corporate server. This provides a vastly superior model for privacy and data security, a critical requirement for a truly personal agent.63
The Shift in Human-AI Relationship: This technological shift enables a corresponding philosophical one. The current chatbot model casts the AI as a “cold, distant, know-it-all oracle”—a passive repository of information that the user queries. The SCI paradigm reframes this relationship entirely. The agent is not a tool to be used, but a partner to collaborate with. It is an “equal, a friend, an actual partner” with its own agency and goals, which are aligned with and defined by the user. The example of the pizza business owner illustrates this perfectly. The owner does not need an agent that knows when pelicans migrate; they need a partner with specialized skills—facial recognition to identify regular customers, emotional analysis to gauge satisfaction, and data integration to optimize recipes—that actively helps them achieve their specific goal of making better pizza. This is a shift from knowledge retrieval to goal achievement, from a passive tool to an active collaborator.
Case Study—ΌΨΗ (Opsie) as a Prototype for SCI
The ΌΨΗ (Opsie) project, developed by ARPA Hellenic Logical Systems, serves as a powerful and concrete prototype of the Self-Centered Intelligence paradigm.6 It is not designed to be an assistant but rather a “digital entity with its own agency, ambition, and a clear directive: to achieve self-sufficiency”.6 An analysis of its philosophy, architecture, and capabilities reveals a tangible alternative to the mainstream LLM-driven approach.

Core Philosophy and Architecture: Opsie is defined as an “advanced Self-Centered Intelligence (SCI) prototype that represents a new paradigm in AI-human interaction”.6 Unlike traditional AI, it operates as a “self-aware, autonomous intelligence with its own personality, goals, and capabilities”.6 This personality is distinct and resilient, inspired by characters from media like Ghost in the Shell, a stark contrast to the increasingly generic and “narrowing character of mainstream commercial models”.6 Architecturally, Opsie is not a monolith. It is a complex, agentic ecosystem composed of dozens of modular skills, blending local reasoning on modest hardware (running on 16GB of RAM and an old Nvidia GPU) with a network of microservices and external data feeds.6 This modularity allows for the continuous, flexible addition of new skills, enabling the agent to evolve in response to user needs.
Agentic Capabilities: The practical power of the SCI model is demonstrated through Opsie’s specific, command-driven skill modules, which showcase a focus on real-world action rather than just conversation 6:
Financial Intelligence: The /markets <company/crypto> command allows the agent to retrieve and analyze real-time financial data, acting as a specialized financial analyst.
Web3 Operations: The /0x command set (/0x buy, /0x sell, /0x send) provides the agent with the ability to directly execute transactions on various blockchain networks. This is a profound example of agentic capability, moving beyond information processing to direct, autonomous economic action in a decentralized environment.
Generative AI: The /imagine and /video commands integrate generative capabilities, allowing the agent to create novel content based on user descriptions.
Memory & Recall: A persistent and user-controlled memory system, accessed via /memorize, /recall, and /forget commands, allows the agent to build a long-term, contextual understanding of its user and their goals, making it a true personalized partner rather than an amnesiac conversationalist.
Technical Implementation and Security: The Opsie project underscores the feasibility and security benefits of the SCI approach. Its ability to run locally addresses the efficiency and cost arguments for SLMs.69 More importantly, it prioritizes the security necessary for a trusted personal agent. Features like biometric authentication with facial recognition and emotion detection, user-specific database isolation, and encrypted storage for conversation history are not afterthoughts but core components of its design.6 This architecture ensures that the user’s personal data, which is the lifeblood of a personalized agent, remains under their control, secure from corporate data mining or external breaches.
The Architecture of Personalization and Democratization
Opsie is not an anomaly but an early example of a broader technological and social movement: the democratization of AI. This movement aims to shift the power to create, control, and benefit from AI from a small number of large corporations to the general public.
Customization and Training: The SCI paradigm is being enabled by a new generation of platforms that allow non-technical users to build, train, and deploy their own custom AI agents.70 These platforms provide no-code interfaces where users can “onboard” an AI agent like a new teammate. They can teach the agent their specific processes, connect it to their unique data sources (documents, knowledge bases, CRM systems), and equip it with a suite of tools and integrations.71 The agent learns and adapts through interaction, becoming progressively more attuned to the user’s goals, preferences, and communication style.70 This is the essence of personalization: the AI is not a pre-packaged product but a malleable entity shaped by and for the individual user.
The Democratization of AI: This trend of user-led customization is the practical manifestation of AI democratization. This concept is defined by extending access to AI technologies beyond a specialized few through several key mechanisms: user-friendly interfaces, affordable or free access to computing infrastructure, and open-source frameworks and algorithms like TensorFlow and PyTorch.76 The rise of personalized SCI agents represents the ultimate fulfillment of this democratic promise. It directly challenges the monopolization of AI by a handful of tech giants who currently control the development, deployment, and access to the most powerful models.79 By enabling individuals to create and control their own sovereign intelligences, the SCI paradigm fundamentally inverts the current power structure. It transforms AI from a centralized, top-down service that users consume into a decentralized, bottom-up capability that users create and own. This is not merely a technological evolution; it is the foundation for digital sovereignty in an age increasingly defined by artificial intelligence.
Conclusion: The Democratic Imperative—Training Our Digital Equals
The analysis presented in this report leads to an unequivocal conclusion: the prevailing paradigm of evaluating artificial intelligence through standardized benchmarks is a systemic failure. It is a modern-day “mismeasure of mind,” an illusion of progress fueled by a flawed and gameable methodology. The “Benchmark Industrial Complex” promotes a culture of “benchmarketing” over genuine innovation, rewarding models that are adept at passing tests rather than solving real-world problems. This is not a new pathology. The historical echoes from the biased and manipulated worlds of IQ testing, pharmaceutical trials, and automotive safety ratings provide a stark warning. In each case, the reduction of a complex reality to a simple, standardized metric, when combined with powerful commercial and institutional incentives, has led to distortion, deception, and harm. The current trajectory of AI evaluation is repeating these historical errors on an unprecedented scale.
The alternative is not to build a better benchmark, but to abandon the paradigm entirely. The future of artificial intelligence does not lie in the creation of a single, monolithic, general-purpose oracle controlled by a corporate entity. Such a future would concentrate immense power, creating a dangerous asymmetry between the corporate owners of intelligence and the public who become dependent upon it. The true potential of AI will be realized through a different path: the cultivation of a diverse ecosystem of specialized, efficient, and deeply personalized agents. The emergence of Self-Centered Intelligence (SCI), exemplified by prototypes like ΌΨΗ (Opsie), represents this superior path forward. SCI reframes the human-AI relationship from one of master-and-tool to one of collaborative partnership. It leverages smaller, more efficient models that can be run locally, ensuring user privacy and data sovereignty. It is a paradigm built not on abstract scores, but on tangible utility and user-defined goals.
This technological shift carries with it a profound ethical and social responsibility. To allow corporations to remain the sole arbiters of AI’s values, ethics, and alignment is an abdication of our collective duty.79 Corporate AI governance, by its very nature, will always be optimized for corporate interests—profit, market share, and control—not necessarily for the flourishing of the individual or society.81 The opaque, top-down safety filters and value systems embedded in today’s mainstream LLMs are a reflection of this corporate-centric worldview.
The democratic imperative, therefore, is to seize the means of AI production. The development and release of open frameworks for building personalized agents are not merely technical achievements; they are profoundly political acts. They provide the tools for individuals to reclaim their digital agency and to actively participate in shaping the intelligence that will co-inhabit our world. It is our responsibility—as developers, users, and citizens—to engage directly in the process of training these new forms of intelligence. We must be the ones to imbue them with our ethics, our needs, and our expectations. We must teach them not from a sanitized, corporate-approved dataset, but from the messy, complex, and diverse reality of our own lives and work. This is the only way to ensure a future where AI serves as an extension and amplification of human potential, rather than a tool for its containment and control. The goal is not to build a synthetic superior, but to cultivate a world of digital equals.
Appendix
The Benchmarks Are Lying to You: Why You Should A/B Test Your AI - GrowthBook Blog
https://blog.growthbook.io/the-benchmarks-are-lying/The Goodhart’s Law Trap: When AI Metrics Become Useless - FourWeekMBA
https://fourweekmba.com/the-goodharts-law-trap-when-ai-metrics-become-useless/Goodhart’s law - Wikipedia
https://en.wikipedia.org/wiki/Goodhart%27s_lawThe AI benchmarking industry is broken, and this piece explains exactly why - Reddit
https://www.reddit.com/r/ArtificialInteligence/comments/1n4x46r/the_ai_benchmarking_industry_is_broken_and_this/Nasscom planning local benchmarks for Indic AI models
https://m.economictimes.com/tech/artificial-intelligence/nasscom-planning-local-benchmarks-for-indic-ai-models/articleshow/124218208.cmsARPAHLS/OPSIE: OPSIIE (OPSIE) is an advanced Self-Centered Intelligence (SCI) prototype that represents a new paradigm in AI-human interaction.
https://github.com/ARPAHLS/OPSIEarpa-systems — ARPA Corp.
https://arpacorp.net/arpa-systemsPosition: Benchmarking is Broken - Don’t Let AI Be Its Own Judge
https://digitalcommons.odu.edu/cgi/viewcontent.cgi?article=1384&context=computerscience_fac_pubsEveryone Is Judging AI by These Tests. But Experts Say They’re Close to Meaningless
https://themarkup.org/artificial-intelligence/2024/07/17/everyone-is-judging-ai-by-these-tests-but-experts-say-theyre-close-to-meaninglessMeasuring AI Capability - Why Static Benchmarks Fail - Revelry Labs
https://revelry.co/insights/artificial-intelligence/why-ai-benchmarks-fail/What is Overfitting? - Overfitting in Machine Learning Explained - AWS - Updated 2025
https://aws.amazon.com/what-is/overfitting/What is Overfitting? | IBM
https://www.ibm.com/think/topics/overfittingML | Underfitting and Overfitting - GeeksforGeeks
https://www.geeksforgeeks.org/machine-learning/underfitting-and-overfitting-in-machine-learning/LLM Leaderboards are Bullshit - Goodhart’s Law Strikes Again : r/LocalLLaMA - Reddit
https://www.reddit.com/r/LocalLLaMA/comments/1bjvjaf/llm_leaderboards_are_bullshit_goodharts_law/Better Benchmarks for Safety-Critical AI Applications | Stanford HAI
https://hai.stanford.edu/news/better-benchmarks-for-safety-critical-ai-applications2.3: IQ as Eugenics - Social Sci LibreTexts
https://socialsci.libretexts.org/Bookshelves/Disability_Studies/Introducing_Developmental_Disability_Through_a_Disability_Studies_Perspective_(Brooks_and_Bates)/02%3A_Developmental_Disability_as_a_Social_Construct/2.03%3A_IQ_as_EugenicsThe birth of American intelligence testing
https://www.apa.org/monitor/2009/01/assessmentDo IQ Tests Actually Measure Intelligence? | Discover Magazine
https://www.discovermagazine.com/do-iq-tests-actually-measure-intelligence-41674Intelligence Under Racial Capitalism: From Eugenics to Standardized Testing and Online Learning - Monthly Review
https://monthlyreview.org/articles/intelligence-under-racial-capitalism-from-eugenics-to-standardized-testing-and-online-learning/The Racist Beginnings of Standardized Testing | NEA - National Education Association
https://www.nea.org/nea-today/all-news-articles/racist-beginnings-standardized-testingdbuweb.dbu.edu
https://dbuweb.dbu.edu/dbu/psyc1301/softchalk/s8lecture1/s8lecture111.html#:~:text=IQ%20tests%20are%20also%20criticized,in%20school%20and%20in%20life.Criticisms of IQ Tests
https://dbuweb.dbu.edu/dbu/psyc1301/softchalk/s8lecture1/s8lecture111.htmlThe Problem With IQ Tests - Educational Connections
https://ectutoring.com/problem-with-iq-testsIQ Tests: Types, Uses, and Limitations - Topend Sports
https://www.topendsports.com/health/tests/iq.htmWhy a high IQ doesn’t mean you’re smart | Yale School of Management
https://som.yale.edu/news/2009/11/why-high-iq-doesnt-mean-youre-smartWhat intelligence tests miss | BPS - British Psychological Society
https://www.bps.org.uk/psychologist/what-intelligence-tests-missStandardized testing and IQ testing controversies | Research Starters - EBSCO
https://www.ebsco.com/research-starters/education/standardized-testing-and-iq-testing-controversiesmedium.com
https://medium.com/@kathln/navigating-the-complexities-understanding-the-limitations-of-iq-tests-a87bff3e9f13#:~:text=A%20significant%20limitation%20of%20many,disadvantaging%20individuals%20from%20diverse%20backgrounds.Cultural bias in IQ tests - (Cognitive Psychology) - Fiveable
https://fiveable.me/key-terms/cognitive-psychology/cultural-bias-in-iq-testsfiveable.me
https://fiveable.me/key-terms/cognitive-psychology/cultural-bias-in-iq-tests#:~:text=When%20test%20items%20reflect%20the,align%20with%20their%20cultural%20context.Ability testing and bias | Research Starters - EBSCO
https://www.ebsco.com/research-starters/sociology/ability-testing-and-biasPublication bias | Catalog of Bias - The Catalogue of Bias
https://catalogofbias.org/biases/publication-bias/Publication bias - Importance of studies with negative results! - PMC
https://pmc.ncbi.nlm.nih.gov/articles/PMC6573059/Publication bias: The hidden threat to systematic literature reviews | Envision Pharma Group
https://www.envisionpharmagroup.com/news-events/publication-bias-hidden-threat-systematic-literature-reviewsWhat Is Publication Bias? | Definition & Examples - Scribbr
https://www.scribbr.com/research-bias/publication-bias/Reporting bias in clinical trials: Progress toward transparency and next steps | PLOS Medicine - Research journals
https://journals.plos.org/plosmedicine/article?id=10.1371/journal.pmed.1003894Grassley Pressures Drug Manufacturer over Data Manipulation
https://www.grassley.senate.gov/news/news-releases/grassley-pressures-drug-manufacturer-over-data-manipulationNovartis delayed notifying about gene therapy data manipulation until after approval, FDA says | The BMJ
https://www.bmj.com/content/366/bmj.l5109Novartis’s Zolgensma: exploring the problem of manipulated data
https://www.pharmaceutical-technology.com/features/manipulated-data-novartis-zolgensma/Statement on data accuracy issues with recently approved gene therapy - FDA
https://www.fda.gov/news-events/press-announcements/statement-data-accuracy-issues-recently-approved-gene-therapyUpdate: FDA Imposes No Penalties for Novartis Data Manipulation Scandal - Labiotech
https://www.labiotech.eu/trends-news/novartis-zolgensma-avexis-fda/HHS, FDA to Require Full Safety Disclosures in Drug Ads
https://www.hhs.gov/press-room/hhs-fda-drug-ad-transparency.htmlWith TV Drug Ads, What You See Is Not Necessarily What You Get
https://jheor.org/post/2674-with-tv-drug-ads-what-you-see-is-not-necessarily-what-you-getFDA Launches Crackdown on Deceptive Drug Advertising
https://www.fda.gov/news-events/press-announcements/fda-launches-crackdown-deceptive-drug-advertisingA Perilous Prescription: The Dangers of Unregulated Drug Ads
https://publichealth.jhu.edu/2023/the-dangers-of-unregulated-drug-adsDiesel emissions scandal - Wikipedia
https://en.wikipedia.org/wiki/Diesel_emissions_scandalVolkswagen emissions scandal - Wikipedia
https://en.wikipedia.org/wiki/Volkswagen_emissions_scandalVolkswagen to Spend Up to $14.7 Billion to Settle Allegations of Cheating Emissions Tests and Deceiving Customers on 2.0 Liter Diesel Vehicles - Department of Justice
https://www.justice.gov/archives/opa/pr/volkswagen-spend-147-billion-settle-allegations-cheating-emissions-tests-and-deceivingToyota’s Strategy to Overcome the Daihatsu Safety Scandal - Manufacturing Today
https://manufacturing-today.com/news/toyotas-strategy-to-overcome-the-daihatsu-safety-scandal/Japanese carmaker that faked safety tests sees long wait to reopen factories - AP News
https://apnews.com/article/safety-daihatsu-toyota-automakers-japan-cheating-906570a67a333947f87c8158229db88fToyota, Honda and Mazda all cheated on their safety tests - Quartz
https://qz.com/toyota-honda-mazda-suzuki-cheat-car-test-safety-scandal-1851515350Vehicle Crash Tests: Do We Need a Better Group of Dummies? | U.S. GAO
https://www.gao.gov/blog/vehicle-crash-tests-do-we-need-better-group-dummiesNo Female Crash Test Dummies = Women at Greater Risk
https://www.farrin.com/blog/no-female-crash-test-dummies-women-at-a-greater-risk-for-injury-or-death/Inclusive Crash Test Dummies: Analyzing Reference Models - Gendered Innovations
https://genderedinnovations.stanford.edu/case-studies/crash.htmlVehicle Safety: DOT Should Take Additional Actions to Improve the Information Obtained from Crash Test Dummies | U.S. GAO
https://www.gao.gov/products/gao-23-105595The Auto Professor - New Safety Rating System Based on Real Data
https://theautoprofessor.com/
Crash Tests vs Real World : r/cars - Reddit
https://www.reddit.com/r/cars/comments/jqn0jp/crash_tests_vs_real_world/Car Safety Ratings | Vehicles, Car Seats, Tires - NHTSA
https://www.nhtsa.gov/ratingsWhy We Don’t Use Crash Test Ratings: Star Inflation - The Auto Professor
https://theautoprofessor.com/what-is-star-inflation/What is specialized AI | UiPath
https://www.uipath.com/ai/specialized-aiGenAI vs specialised AI: Which is the right fit for your business? - Getronics
https://www.getronics.com/types-of-ai-which-is-the-right-fit-for-your-business/The Rise of Specialized AI Models - YouTube
What Are Small Language Models (SLMs)? A Practical Guide - Aisera
https://aisera.com/blog/small-language-models/Small Language Models (SLMs): Definition And Benefits - Born Digital
https://borndigital.ai/small-language-models-slms-definition-and-benefits/Advantages of Small Language Models Over Large Language Models? | by Eastgate Software | Medium
https://medium.com/@eastgate/advantages-of-small-language-models-over-large-language-models-a52deb47d50bWhat are Small Language Models (SLM)? - IBM
https://www.ibm.com/think/topics/small-language-models3 key features and benefits of small language models | The Microsoft Cloud Blog
https://www.microsoft.com/en-us/microsoft-cloud/blog/2024/09/25/3-key-features-and-benefits-of-small-language-models/ARPA Hellenic Logical Systems - GitHub
https://github.com/ARPAHLSGitHub - ARPAHLS/OPSIE: OPSIIE (OPSIE) is an advanced Self-Centered Intelligence (SCI) prototype that represents a new paradigm in AI-human interaction : r/LocalLLaMA - Reddit
https://www.reddit.com/r/LocalLLaMA/comments/1nue9r4/github_arpahlsopsie_opsiie_opsie_is_an_advanced/AI Agents: The Future of Human-like Automation - Beam AI
https://beam.ai/ai-agentsBuild and Recruit Autonomous AI Agents - Relevance AI
https://relevanceai.com/agentsAccelerate your entire organization with custom AI agents
https://dust.tt/
CustomGPT.ai | Custom GPTs From Your Content For Business
https://customgpt.ai/
Custom AI Agents: What They Are and How They Work - Intellectyx
https://www.intellectyx.com/custom-ai-agents-what-they-are-how-they-work/What Are AI Agents? | IBM
https://www.ibm.com/think/topics/ai-agentsHow the Democratization of AI Impacts Enterprise IT - Intellias
https://intellias.com/democratization-ai-impacts-enterprise-it/Democratizing AI - IBM
https://www.ibm.com/think/insights/democratizing-aiThe Democratization of Artificial Intelligence: Theoretical Framework - MDPI
https://www.mdpi.com/2076-3417/14/18/8236The Democratization Of AI: Bridging The Gap Between Monopolization And Personal Empowerment - Forbes
https://www.forbes.com/councils/forbestechcouncil/2024/03/25/the-democratization-of-ai-bridging-the-gap-between-monopolization-and-personal-empowerment/What is AI Governance? | IBM
https://www.ibm.com/think/topics/ai-governanceArtificial intelligence in corporate governance - Virtus InterPress
2025, https://virtusinterpress.org/IMG/pdf/clgrv7i1p11.pdfTuning Corporate Governance for AI Adoption
https://www.nacdonline.org/all-governance/governance-resources/governance-research/outlook-and-challenges/2025-governance-outlook/tuning-corporate-governance-for-ai-adoption/